
一,知识框架
1. 首先,需要重点理解元字符,限定符,分枝条件,分组,反义
2. 其次,深入了解后向引用,零宽断言,负向零宽断言。
二,知识要点
1.元字符
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
2.限定符
| 代码/语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
3.分枝条件: |
a) 0\d{2}-\d{8}|0\d{3}-\d{7} :
这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。
b) \(0\d{2}\)[- ]?\d{8}|0\d{2}[- ]?\d{8} :
这个表达式匹配3位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔。你可以试试用分枝条件把这个表达式扩展成也支持4位区号的。
c) \d{5}-\d{4}|\d{5} :
这个表达式用于匹配美国的邮政编码。美国邮编的规则是5位数字,或者用连字号间隔的9位数字。之所以要给出这个例子是因为它能说明一个问题:使用分枝条件时,要注意各个条件的顺序。如果你把它改成\d{5}|\d{5}-\d{4}的话,那么就只会匹配5位的邮编(以及9位邮编的前5位)。原因是匹配分枝条件时,将会从左到右地测试每个条件,如果满足了某个分枝的话,就不会去再管其它的条件了。
4.分组:用小括号来指定子表达式(也叫做分组)
a) (\d{1,3}\.){3}\d{1,3}
这是一个简单的IP地址匹配表达式。要理解这个表达式,请按下列顺序分析它:\d{1,3}匹配1到3位的数字,(\d{1,3}\.){3}匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个一到三位的数字(\d{1,3})。
5.反义:
| 代码/语法 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字 |
a) \S+ : 匹配不包含空白符的字符串。
b) <a[^>]+> : 匹配用尖括号括起来的以a开头的字符串(这个例子宜重点留意)
- 虽然组号是从左向右进行分配,但是扫描两遍,第一遍先分配给未命名的分组,第二遍再分配给命名的分组。所以命名后的分组组号会更大
- 使用(?:exp)可以使一个分组不分配组号,如(?:ab)?(c|C)d\2D中(ab)就没有分配到组号,而(c|C)组号为1
人性是贪婪的,正则表达式与人一样也是贪婪的。一个正则表达式会尽量多的去匹配字符串,如:ab.+c去匹配’abccccc’是会将该字符串全部匹配出来。但有时候我们只想要其匹配’abcc’,此时怎么办呢?需要给正则表达式中表示数量的元字符加一个?变成ab.+?c。此时该正则表达式就变懒了,不会再去匹配那么多,匹配到‘abcc’就完事了。
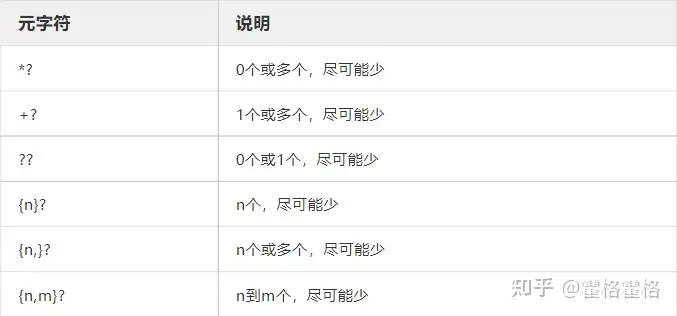
这两个个概念有些不太好理解。正如前面所说这两个也是表示位置的元字符。从字面意思上理解,零宽代表其没有宽度,即如之前介绍表示位置的元字符中提到的一样,不会实际占用字符。
断言是什么?是assert,是用来判断条件是True还是False。理解完这两个词语的意思后,零宽断言的概念应该也就能理解了。那么负向无非就是它的反义词。
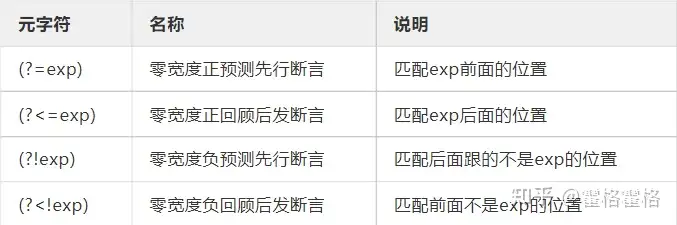
上面的表格主要看第一列它是什么格式就好,反正后面的名称和说明也很难看懂。接下来我来用自己的理解通俗的解释一下这些概念。
首先字符串中可以有四种方式确认某个子字符串的位置,如字符串‘BACAB’中有两个A,A前面是B、A前面不是B、A后面是C、A后面不是C。上述四种条件都能够匹配出唯一一个子字符串A。这个例子大概理解的话就可以往后看了。
- (?=exp)中exp指代的是任意元字符的组合,结合具体的例子来理解该元字符的用法,一个正则表达式为A(?=C),它代表的情况就是A后面是C的情况。所以匹配出了第一个A,由于该元字符是零宽所以它只能匹配出A而不是AC。
- (?<=exp)与上面用法相反,一个正则表达式为(?<=B)A,它代表的情况就是A前面是B的情况。所以匹配出了第一个A。如果改成(?<=C)A,则能匹配出第二个A。
- (?!exp)的例子为:A(?!C),它代表的情况为A后面不是C,所以匹配出第二个A。
- (?<!exp)的例子为:(?<!B)A,它代表的情况为A前面不是B,所以匹配出第二个A。
通过上面四个例子的介绍,应该对于这两个概念、四个元字符有了了解。理解是重点,记下来也是重点。本人是这样记下来的,四个元字符的基本格式都是(?),只不过问号后面的不一样。分下面两种情况: - XXX前/后是XXX的话就写一个=,XXX前/后不是XXX的话就写一个!。这个和日常用的=和!=差不多。
- 如果表示的意思是前的话,这个元字符就需要出现在前面且要加一个类似于向前指的箭头<。如果表示的意思是后的话,就什么都不需要加。
通过上面两个情况的归纳,是不是这四个元字符就都记下来了?
到目前为止,正则表达式的基本内容都介绍完了。但是文中用的例子都比较简单,只能帮助你理解概念。如果感兴趣或者工作中能用到的话,还需要后续勤加练习
